Local Memo: Meta Takes on Twitter with Threads

Share

Local Memo: Meta Takes on Twitter with Threads
In this week’s update, learn about the swift growth of Meta’s new app, Threads; Twitter’s reversal on public access to its content; ChatGPT’s shutdown of web access and rollout of the code interpreter plugin; Google’s plan to examine robots.txt alternatives; the shutdown of GBP call tracking; and synchronization between LSA and GBP.
Meta Takes on Twitter with Threads
What a difference a week makes. Just last week in this space, I reported on the imminent launch of Threads, Meta’s Twitter clone. Now, Threads is on its way to becoming the fastest-growing app in history, with over 97 million downloads in its first five days. Threads is a kind of sister app to Instagram, allowing users to port over their Instagram accounts and followers, which has a lot to do with the new app’s swift rise in popularity. By contrast, ChatGPT reached 100 million users in about two months. Earlier successes, like Instagram itself, took much longer – two and a half years in Instagram’s case.
Instagram has 1.6 billion users outside the EU (where Threads is not yet available). Assuming the bulk of Threads users came over from Instagram, currently only 6% of Instagram’s user base is trying the new app, suggesting its rapid growth could continue for some time.
Like many Meta apps, Threads gathers a large amount of data from users by default, causing some users to raise privacy concerns. A notice when signing up to use Threads indicates that it may gather information linked to user identities including contact info, user content, browsing history, purchases, “sensitive info,” and several other categories.
Twitter has sent a cease and desist letter to Meta regarding Threads, accusing the company of “unlawful misappropriation” of Twitter’s intellectual property.
Threads terms posted by Meta on the app, courtesy Search Engine Journal
Twitter Restores Access to Its Content for Google and Others
In yet another quick turnaround, Twitter has restored access to its content to users who are not logged in to the Twitter app, reversing a decision made just days before. As of Monday, July 3, Google announced that it had stopped crawling Twitter content and incorporating it into search results, given the restrictions the company imposed, it said, to cut down on data scraping utilized for purposes such as building large language models. Note that Twitter content has been featured prominently in Google results for some time, presumably driving significant traffic to the app. By Thursday, July 5, Twitter had reversed its decision. Google is now indexing Twitter content as before, though Twitter has added an overlay asking users to log in to the app.
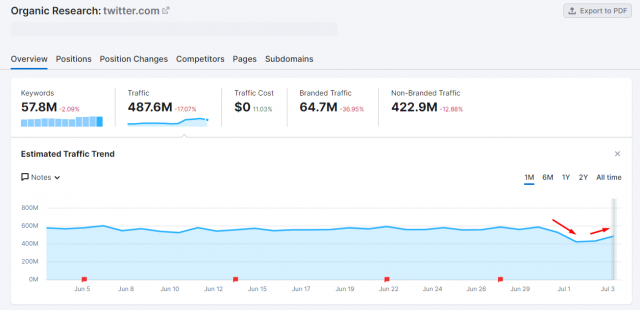
SEMrush shows massive dip in Twitter traffic during the self-imposed outage, courtesy Glenn Gabe / Search Engine Roundtable
ChatGPT Turns Off Web Access, Rolls Out Code Interpreter
At least temporarily, OpenAI has shut down ChatGPT’s access to the internet. The company announced that that move was made “out of an abundance of caution” when it was alleged that ChatGPT was providing access to content that should have been hidden behind the paywalls of publishers such as Fortune Magazine. ChatGPT’s web access, powered by Bing, was first announced in March. OpenAI says it will fix the issue.
In related news, all ChatGPT Plus users should now have access to the code interpreter plugin, also announced in March, which has been rolling out more slowly than the web access plugin. Aside from writing and editing code, the code interpreter plugin is reportedly very good at analyzing uploaded data and creating charts and graphs.
I got access to the ChatGPT Code Interpreter model. I fed it a queries GSC export with the prompt “Classify each query for seo intent and then sum each classification bucket’s clicks and display in a bar graph”. It’s essentially a fine tuned agent. It simply writes/runs python. pic.twitter.com/RmGGLy7UoW
— Greg Bernhardt 🐍🌊 (@GregBernhardt4) May 9, 2023
Google Examines Robots.txt Alternatives
Google says the company is “kicking off a public discussion” about possible alternatives to the robots.txt protocol for communicating website preferences to search engines. Robots.txt, which allows web pages to tell search engines whether or not they should be indexed, was developed almost 30 years ago, “before new AI and research use cases” that may call for a new standard. Google wants to “explore additional machine-readable means for web publisher choice and control,” according to the company’s statement. Google is inviting public comment on this issue and has made a web form available through which users can join a mailing list on the topic.
GBP Shuts Down Call Tracking
Ben Fisher recently shared on Twitter that Google has “silently” removed the call tracking feature from Google Business Profiles, commenting, “Good riddance, that was a buggy mess that would redirect calls to other merchants.” The feature, officially called Call History, was never fully rolled out by Google and remained in limited release since it was first announced in 2020. It displayed basic data on calls received by a business, but required the use of a Google forwarding number which announced to callers that Google was routing their calls. Further discussion of the feature’s removal can be found at the Local Search Forum.
LSA Updates Will Now Sync with GBP
Ben Fisher also broke the news that Google is now syncing updates between Local Service Ads and Google Business Profiles, such that when data such as hours of operation is updated in a Local Service Ads profile, the same update will be reflected in the Google Business Profile within about 24 hours. It’s not immediately clear how many fields are supported or whether updates work in the opposite direction. Barry Schwartz points out that the new synchronization may show that LSA and GBP are “getting closer together.”
Related Articles




